SQL At A Glance
This text is a self-study to learn how use SQL to work with the databases.
Contents
- Introduction
- Premier
- Open Database
- Create Database
- Selecting Data
- Add, Delete, Remove
- Sorting and Removing Duplicates
- Filtering
- Calculation on variable
- Combining variables
- Missing Data
- Aggregation
- Combining Data
- Output file
- SQL in R
- SQL in Python
- References
Introduction
Data can be stored in different formats and each software has own structures. Since the data should be handled with different softwares, there are few options that most data scientists use for storing data: text-file, spreadsheet, and database. The database is very good for big and complex dataset. One of best way working with database is to use the Structured Query Language (SQL) which allows work with database through queries. There are several softwares designed for working with SQL, e.g., mysql, postgresql, MS Access, and MS SQL Server. Here we use sqlite3 which is a lightweight database software written in C that does not need a server. It runs on the terminal, although there are a couple of database softwares (e.g., DB Browser for SQLite) that functionally work with sqlite3. SQLite commend also can be run from Python and R.
To fix definition for the rest of this note; the database is a file that stores related tables, the table includes rows and columns. Often the column is referred to as variable or fields and the row as observation and records.
This text has three companions; 1)practice.db that is a fake database for the practice, 2)Challenge, after each section, we provide a challenge which include questions related to the section and readers can test their learning. We also added the correct solutions. 3)survey.db it is a database used in [sw], we use it for the challenge part.
Premier
After installing sqlites, type sqlite3 in terminal to get into the software:
Last login: Fri Sep 6 17:12:01 on ttys000
SAM-MacBook:~ user1$ sqlite3
SQLite version 3.24.0 2018-06-04 14:10:15
Enter ".help" for usage hints.
Connected to a transient in-memory database.
Use ".open FILENAME" to reopen on a persistent database.
sqlite>
sqlite> .quit
SAM-MacBook:~ user1$
To quit sqlites type .quit.
Open Database
In this self-study text, we used simple database called practice.db to describe sqlite3. In order to load the database, type sqlite3 name_of_database.
SAM-MacBook:~ user1$ sqlite3 practice.db
SQLite version 3.24.0 2018-06-04 14:10:15
Enter ".help" for usage hints.
sqlite>
To load a database from inside sqlite3, type .open name_of_database
sqlite> .open practice.db
To see the list of tables type .tables, more detail of tables can be obtained using .schema.
sqlite> .tables
employees expenses
sqlite> .schema
CREATE TABLE expenses (id INTEGER, food_expense DECIMAL, automobile_expense DECIMAL, travel_expense DECIMAL, date DATE);
CREATE TABLE employees (id INTEGER, name TEXT, family TEXT);
It shows the database has two tables,
- expenses: the expenses of trip done by employees.
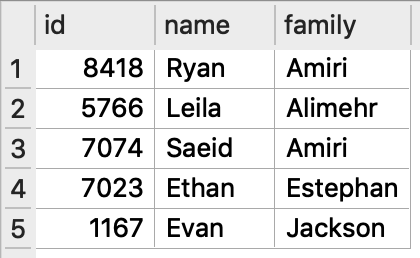
- employees: the list of employees in a company.
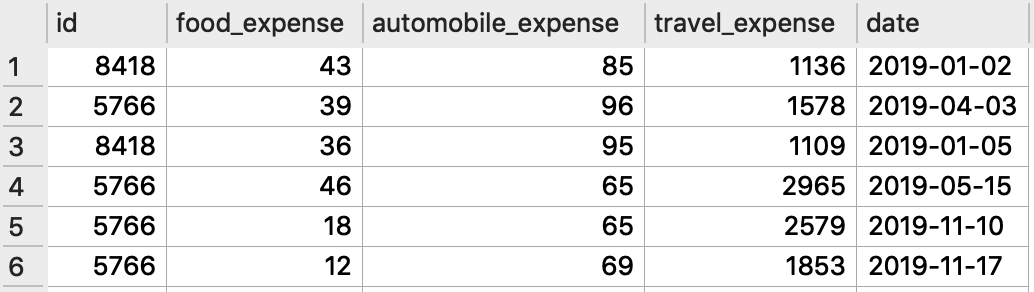
Tables in the database are often related to each other using a unique identifier, which often called key. The identifiers store in a key column or common columns. For the practice.db database, the employee id does this role.
Challenge 1
Go to Challenge 1 and answer the questions.
Create Database
As mentioned a collection of tables constructs a database, to create a table type CREATE TABLE NAME_OF _TABLES(VARIABLES). The following script shows how to create a table Newemployew:
CREATE TABLE Newemployee(id integer, name text, family text, contract text);
It has four columns (id, personal, family, contract), except id the rests have the text format.
The columns in table can have different formats, see www.sqlite.org
| Type | Description | More details |
|---|---|---|
| INTEGER | integer | |
| REAL | a floating point number | REAL,DOUBLE,DOUBLE PRECISION, FLOAT |
| NUMERIC | numberic can be broad see | NUMERIC,DECIMAL(10,5),BOOLEAN,DATE,DATETIME |
| TEXT | string | |
| NULL | the Null values | |
| BLOB | Binary Large OBject |
Challenge 2
Go to Challenge 2 and answer the questions.
Selecting Data
To see the records of table, type
SELECT names_of_variables FROM Name_of_table;
SELECT family, id FROM employees;
To have a tidy display in sqlite3, type the following codes.
.mode column
.header on
Challenge 3
Go to Challenge 3 and answer the questions.
Add, Delete, Remove
Once a table is created, one can add, change, and remove the recodes using INSERT, UPDATE, and DELETE, respectively.
You can insert directly the records into the table;
INSERT INTO TB(Col1, Col2, ...) VALUES(Val1, Val2, ...)
where the values of (Val1, Val2, ...) are inserted in the (Col1, Col2, ...). If you are adding to all the columns, drop the name of table.
INSERT INTO employees VALUES(1752,'ALex','Nickson');
INSERT INTO employees(id,name,family) VALUES(1752,'ALex','Nickson');
The records can be inserted from other table:
CREATE TABLE employees_b(name TEXT, family TEXT);
INSERT INTO employees_b SELECT name, family FROM employees;
The following simple code shows how to modify an existing record:
UPDATE employees SET id=7152 WHERE name='ALex';
So the general format of update is UPDATE TB SET Col1=Val1, Col1=Val1,..., WHERE condition.
By specifying the record, one can drop it from table:
DELETE FROM employees WHERE id=7152;
To drop table, just type names of tables after DROP TABLE, the following script drops the Survey table,
DROP TABLE Newemployee;
DROP TABLE employees_b;
Challenge 4
Go to Challenge 4 and answer the questions.
Sorting and Removing Duplicates
To remove the duplicate, add DISTINCT in front the column name
SELECT DISTINCT family FROM employees;
In order to sort, add an ORDER BY clause to the query.
SELECT * FROM employees ORDER BY id;
The default of ordering is the ascending order, to sort in the opposite order, add DESC. The following query shows how add multiple orders with different requests:
SELECT id, travel_expense, automobile_expense, food_expense FROM expenses ORDER BY id DESC, travel_expense ASC ;
Challenge 5
Go to Challenge 5 and answer the questions.
Filtering
To select the records for a give criterion, add the WHERE clause with the record of interest.
SELECT * FROM expenses WHERE id=1167;
By using Logical AND and OR can add more criteria,
SELECT * FROM expenses WHERE id=5766 AND travel_expense < 2000;
SELECT * FROM expenses WHERE id=5766 OR id=1167;
SELECT * FROM employees WHERE family IN ('Amiri', 'Alimehr');
Filtering can be done using particular criteria, apply the LIKE clause. The following query selects records in family where they start with A.
SELECT * FROM employees WHERE family LIKE 'A%';
Different combination of them can also be used; %A, %A%.
Challenge 6
Go to Challenge 6 and answer the questions.
Calculation on variable
Simple arithmetic can be done in sqlite3 as well,
SELECT 4+2;
SELECT 4-2;
SELECT 4+2, 4-2;
SELECT 4*2;
SELECT 4/2;
Calculation can be done on the selected variables.
SELECT 1.02*travel_expense FROM expenses WHERE automobile_expense<200;
SELECT travel_expense, round(4*(travel_expense-100)/8,2) FROM expenses WHERE id IN (1167, 5766);
Challenge 7
Go to Challenge 7 and answer the questions.
Combining variables
One can combine variables using ||,
SELECT name || family FROM employees;
SELECT name || ' ' || family FROM employees;
SELECT family || ', ' || name FROM employees;
If you want to combine the output of two queries use the UNION clause between them.
SELECT * FROM employees WHERE name='Saeid' UNION SELECT * FROM employees WHERE name='Leila';
The UNION drops the duplicate, and actually run DISTINCT on it as default. If there is not a duplicate in output of two query, use UNION ALL which is faster than UNION.
To clean identifier, one can use substr(variable, s, l), it cuts record from starting point s for length l.
SELECT DISTINCT substr(id, 1, 3) AS Majoremployee FROM employees;
Challenge 8
Go to Challenge 8 and answer the questions.
Missing Data
Missing, empthy, or NULL is part of database, SQL easily handle missing,
SELECT * FROM expenses WHERE id IS NULL;
SELECT * FROM expenses WHERE id IS NOT NULL;
SELECT * FROM expenses WHERE id = 8418 AND travel_expense IS NULL;
Challenge 9
Go to Challenge 9 and answer the questions.
Aggregation
You can retrieves the Statistical summary of variable for other variables, the following scripts generate mean and min of variable reading.
SELECT avg(travel_expense) FROM expenses;
SELECT avg(travel_expense) FROM expenses WHERE id = 8418;
SELECT min(travel_expense) FROM expenses WHERE id = 8418;
Sometimes should find a summary statistics of variable for another variables
SELECT id, count(*) FROM expenses WHERE id = 8418 AND travel_expense <= 2000;
SELECT id, count(*),max(travel_expense), sum(travel_expense) FROM expenses;
Challenge 10
Go to Challenge 10 and answer the questions.
Combining Data
Using the JOIN clause can creates the cross product of two tables.
SELECT * FROM employees JOIN expenses;
In order to match the data with an index in both dataset, use WHERE or ON.
SELECT * FROM employees JOIN expenses WHERE employees.id = expenses.id;
You can select
SELECT employees.name, employees.family, expenses.travel_expense
FROM employees JOIN expenses
ON employees.id = expenses.id;
SELECT employees.name, employees.family, expenses.travel_expense
FROM employees JOIN expenses
ON employees.id = expenses.id
AND expenses.travel_expense IS NOT NULL
AND expenses.travel_expense !=0;
Challenge 11
Go to Challenge 11 and answer the questions.
Output file
The tables can be saved in the standard format. SQL has several arguments to save file with a correct formant, .header, .mode, .separator. The name of output file can be written in front .once and .output.
.header on
.mode csv
.separator ,
.once dataout.csv
SELECT * FROM employees;
.mode csv
.output data.csv
SELECT * from expenses;
The table saved in can be imported to sql
.mode csv
.import dataout.csv id
To see the output as temporary file out of terminal, type
.output '|open -f'
SELECT * from employees;
.excel
SELECT * from employees;
Once the operations done, you can save it or create a new database using .save file.bd.
.save practic_new.db;
Challenge 12
Go to Challenge 12 and answer the questions.
SQL in Python
In order to work with sqlite3 in Python you need to import the import sqlite3. You don’t need to install sqlite3 module, because it is standard library. To jump in, run the following codes:
import sqlite3
conn = sqlite3.connect("Practice.db") # establishes a connection to database.
cc = conn.cursor() # keeps track of where we are in the database.
cc.execute("SELECT family, name FROM employees;") # executes the query in sqlite
results = cc.fetchall() # brings them to Python.
results
The result is stored as list in Python and can work on data in Python. Any query we learned can be done inside cursor.execute().
Once the data is brought, you should disconnect Python
cursor.close()
conn.close()
You can find more in [dpo], [sw2], and [qc].
SQL in R
In order to run a query inside the R’s code, you need to load library(RSQLite), the following lines show: 1) load R’s Library, 2) connect to database, and 3) executing the query.
library(RSQLite)
conn <- dbConnect(SQLite(), "practice.db")
results <- dbGetQuery(conn, "SELECT family, name FROM employees;")
results
The result of running query is store as data.frame in R. Once running the query is done, disconnect it; dbDisconnect(connection). Good references for working with sqlite in R are [wdc], [dor], and [sw3].
RStudio provides an editor for working with Sqlite, which is accessible using File>New File> SQL Script, so the discussed queries can be run from RStudio. R has a few libraries that are built to work professionally with the database; DBI provides a database interface, dbplyr is an extension of dplyr to work with database, odbc which is a database interface to Open Database Connectivity (ODBC). A complete list of packages built for working with R can be found in Databases using R.
More reading
There are several online websites for learning Sqlites, we can suggest [w3], [wt], and [qlt].
References
[sw] https://swcarpentry.github.io/sql-novice-survey/
[dpo] https://docs.python.org/3.7/library/sqlite3.html
[sw2] https://swcarpentry.github.io/sql-novice-survey/10-prog/index.html
[gc] https://github.com/CoreyMSchafer/code_snippets/tree/master/Python-SQLite
[dor] https://datacarpentry.org/R-ecology-lesson/05-r-and-databases.html
[wdc] https://www.datacamp.com/community/tutorials/sqlite-in-r
[sw3] https://swcarpentry.github.io/sql-novice-survey/11-prog-R/index.html
[w3] https://www.w3schools.com/sql/sql_create_table.asp
[wt]https://www.techonthenet.com/sql/index.php
[qlt]https://www.sqlitetutorial.net/
License
Copyright (c) 2019 Saeid Amiri and Leila Alimehr


